A New Website for Harper’s Magazine
On December 1, 2003, a new website for Harper’s Magazine launched at Harpers.org. This site was conceptualized, programmed, and designed by myself, under the management of Harper’s senior editor Roger D. Hodge. I also wrote some copy for the site, and have been editing the Archive of pre-1900 articles.
I desperately need a nap, but I thought I’d tell you a bit about the site first.
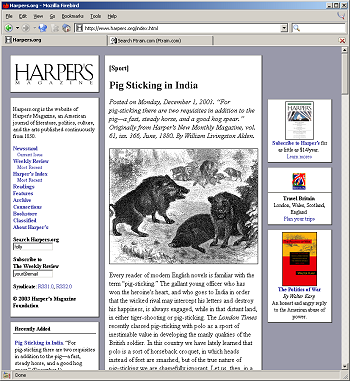
The site looks like this, but larger.
It’s been noted that Harpers.org looks like Ftrain. It’s actually the other way around: Ftrain looks like Harpers.org. I’ve been using you, the Ftrain reader, as a guinea pig for about 5 months, testing ideas I developed for Harper’s, finding out what JavaScript worked in which browser, which interface ideas were too baffling to include, and seeing how you dealt with different sorts of links.
Thanks for that.
Because Ftrain readers are free with both praise and criticism, this turned out to be a good way to craft a site that was accessible, worked in most browsers, and was enjoyable to use (with some practice). Now that Harpers.org is up and its design is stable, Ftrain can change according to my whim, and I can begin to break things here in new ways.
Now, I am going to blow my own horn. Trumpet provided by Leslie Harpold. Ms. Harpold is Ftrain’s preferred visual archivist and art director.
Features of Harpers.org
The regular list of new-age website tomfoolery applies: XHTML/CSS/QXNYTLRPK, accessible for the people, JavaScript zip-zap, validating RSS hoo-ha, etc. The framework is solid XML and XSLT2.0, and plays nice with others. But also:
Remixing Narrative
Harper’s is built upon a Semantic Web framework—albeit a primitive one. I’ve written about what the Semantic Web is, and why it matters before, if you’re curious, so I won’t rehash that here.
Using this framework, Harper’s is divided into two parts: narrative content, like the Features and the Weekly Review, and a taxonomy (or ontology, depending on your preferred term), called Connections.
- The taxonomy is a big list of interconnected topics—examples are Dolly the Sheep, Monkeys, and Satan.
- The Weekly Review, which is narrative content, is description of the events of the past week, published every Tuesday (see an example).
We cut up the Weekly Review into individual events (6000 of them, going back to the year 2000), and tagged them by date, using XML and a bit of programming. We did the same with the Harper’s Index, except instead of events, we marked things up as “facts.”
Then we added links inside the events and facts to items in the taxonomy. Magic occurred: on the Satan page, for instance, is a list of all the events and facts related to Satan, sorted by time. Where do these facts come from? From the Weekly Review and the Index. On the opposite side, as you read the Weekly Review in its narrative form, all of the links in the site’s content take you to timelines. Take a look at a recent Harper’s Index and click around a bit—you’ll see what I mean.
The best way to think about this is as a remix: the taxonomy is an automated remix of the narrative content on the site, except instead of chopping up a ballad to turn it into house music, we’re turning narrative content into an annotated timeline. The content doesn’t change, just the way it’s presented.
Everything is in the Taxonomy
Harpers.org makes almost no distinction between data and metadata. Any block of text can have multiple blocks of text living inside of it (as when the Weekly Review contains events), and these blocks in turn can contain multiple blocks, and so forth. What this means in practice is that in addition to events and facts, I can add any arbitrary kind of data to the site. Links, Litigation, Questions, Answers, Lies, Photos, Crimes, any sort of boundary you can think of. By linking from inside of these boundaries to pages in the taxonomy, the taxonomy pages know to automatically list and sort them, whatever they are. How you display them is up to the XSLT code, and to the way the ontology is structured. Let’s skip over that part.
Another example: the Bookstore is just another part of the site, and the ads for books are automatically generated from the bookstore. Advertising and editorial are produced with the same system using the same linking mechanism. In theory, this would allow by-topic sponsorships similar to keyword-based advertising on search engines: “I’d like this ad to run next to the religion category and on all pages related to religion.”
There’s other stuff under the hood, and I have many plans (dynamically generated maps! queryable content! news-trackers!), but actions speak louder, etc.
No Banner Ads
Banner ads are terrible for both readers and advertisers. We got rid of them for Harper’s, put non-blinking ads to the side, and made them half image, half copy, flexibly sized. This is, I believe, good for brand-building—the advertiser’s message is prominently displayed and persistently there as the user reads. Because this message is not obtrusive and animated, it need not be ignored. Because it is graphical and bold, and lives in its own place to the right, it can be seen as content unto itself, not simply tacked on to make a few spare bucks. The ads are an integral part of the page.
(I wouldn’t mind animated ads, but they should only animate when the user mouses over them and shows interest. “The reader’s freedom is a holy thing,” says William Gass, and I agree.)
Constructing Harpers.org
This was originally going to be a case study of how Harper’s came into being. But only I care about that, and my pomposity has some limits. So I’ll give you the entire thing in 4 bullets.
- Harper’s has been very patient.
- Roger is an editor who knows XML and how to program. His kind are slightly more rare than talking dogs. He took on a great deal of complicated work in order to make this site happen, without even a shrug.
- 3,000 facts, 6,000 events, 12,000 links, 500 topics, and over 939 separate HTML pages. 300,000 words.
- I finished coding the first draft of the site by annotating printouts of XSLT code with a pencil, by propane light, in a 100-year-old log cabin in West Virginia, while muttering.
Next
Now that everything is working fairly well, it’s time to tear the guts out of the code and start again. A small team of Java coders and I are planning to take the work done on Harper’s, and in other places like Rhetorical Device, and create an open-sourced content management system based on RDF storage. This will allow much larger content bases (the current system will start to get gimpy at around 30 megs of XML content—fine for Harper’s, but not for larger sites), and for different kinds of content to be merged. When this will be completed is open to discussion, of course. But it seems like the right next step, if we can just figure out how to find the time to get it done. More later.
Talk to Me
Now that I’ve done this, I’d love to talk about it. If you’re in publishing or a related industry and want to talk to me about any of the work that went into the Sitekit code, for whatever reason, with the idea that I might help you think about your own content, please contact me, arrange a meeting, take me to lunch, throw paper airplanes over the East River from Manhattan in the hope that they will come in through the hole in my screen window, and so on. It’s time for a career change.